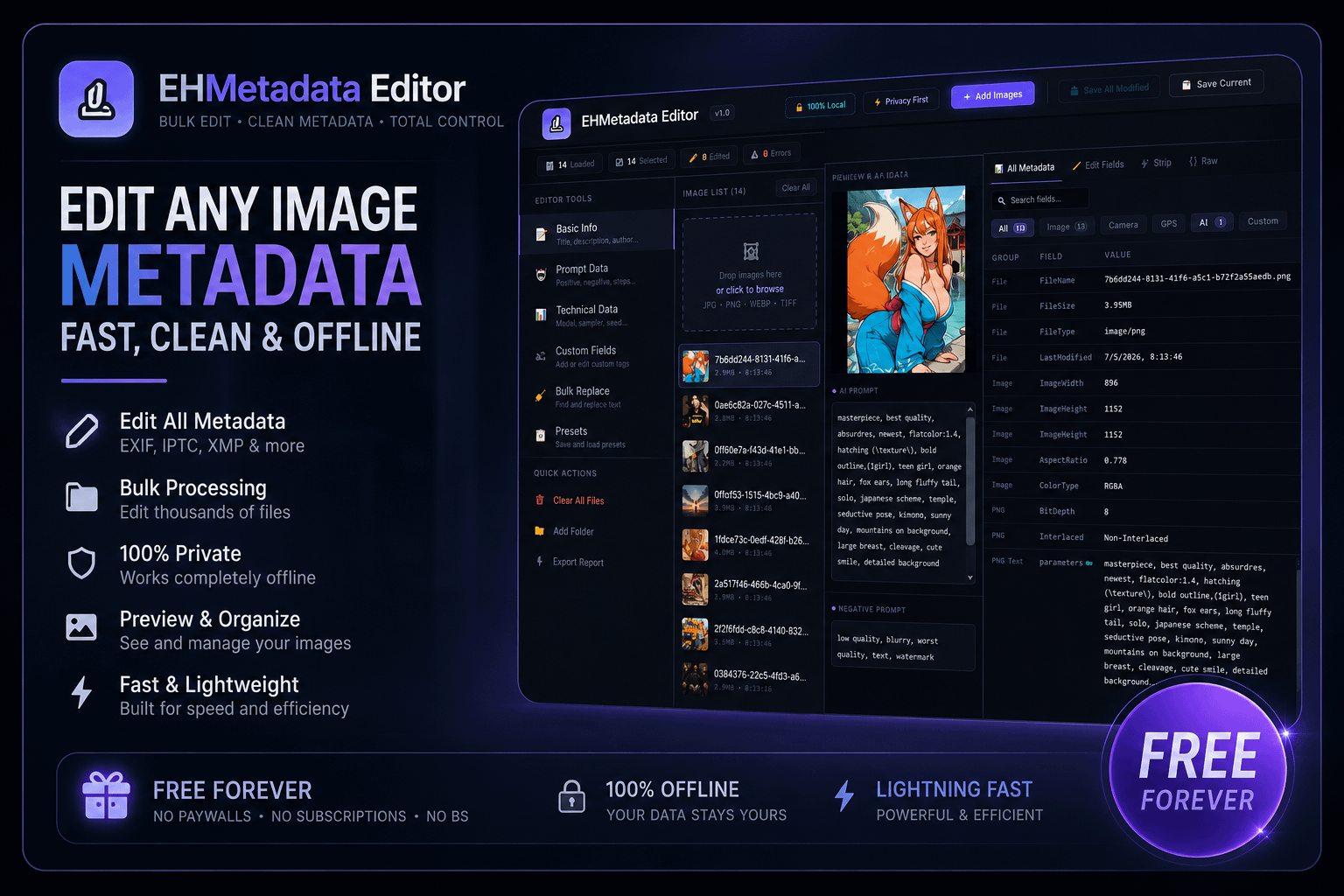
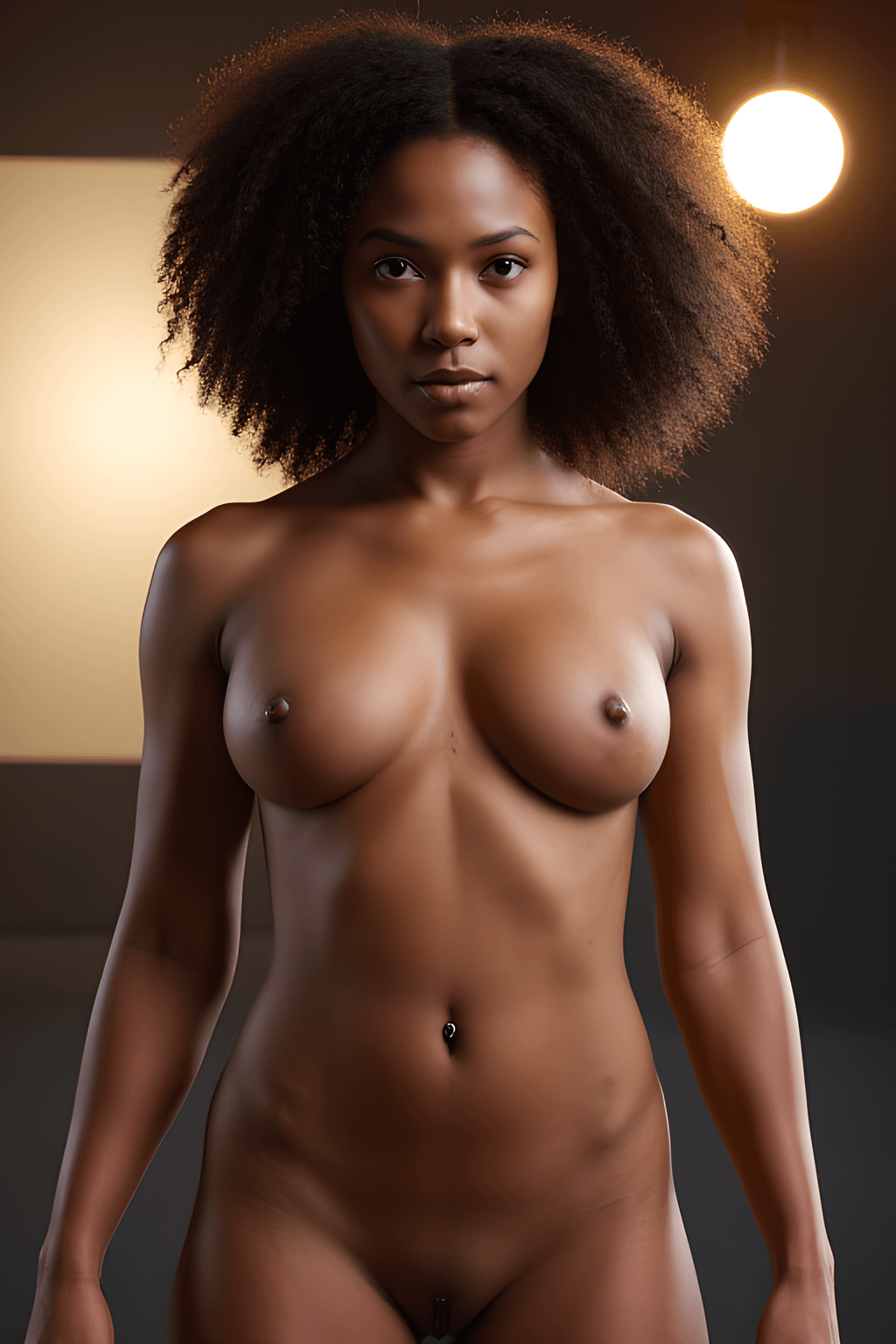Building a pipeline for Manga Decensoring & Outfit Removal on Flux Klein / Qwen Edit. Architecture & Dataset reality check.
Hi everyone.
I’m an experienced trainer (20+ LoRAs on SDXL), currently researching how to build a high-quality pipeline for Manga Decensoring and Character Undressing (img2img). I plan to train a LoRA (or potentially a full checkpoint fine-tune) for Flux Klein or Qwen Image Edit. Before I commit to burning GPU hours, I want to share my research path, hypotheses, and ask the community for a reality check.
1. The Manga Decensoring Pipeline
I keep seeing high-quality AI-decensored uploads on manga archives, so the tech clearly exists. Yet, public tools feel outdated.
- My proposed workflow: Use YOLO for detecting censorship bars/mosaics -> Extract the region -> Use Flux Klein with a Reference Image to inpaint the anatomy while preserving the art style.
- The Question: Is this YOLO+Flux combo the current SOTA approach in 2026? Or is there a more efficient end-to-end model for panel consistency that I'm missing?
2. Character Undressing (The "Hardcoded Prompt" Mystery)
While researching existing models for Qwen/Flux (see references below), I noticed a strange pattern: almost all of them seem to use the exact same hardcoded prompt.
- My Hypothesis: This suggests that everyone is likely training on the same homogenous dataset, causing the models to overfit to a single instruction structure rather than understanding the editing task flexibly.
- My Goal: I want to create a model that actually understands what to remove based on the prompt, rather than just indiscriminately "nuking" clothing on a trigger word.
3. The Dataset & Reasoning Bottleneck
Standard datasets rely on Danbooru tags, which lack spatial reasoning.
- The "Horns" Case (see attached image): Lucoa has 6 head attributes: 2 organic horns, 2 cow ears, and 2 accessory horns.
- The Problem: Standard tagging merges these into "multiple horns." During training, the model tries to remove the organic horns along with the outfit because it doesn't distinguish between anatomy and accessories.
My Solution Strategy:
- Gemini 3 Flash: I am using it right now for my curated dataset because it's the only model that correctly identifies these layers (Anatomy vs. Outfit).
- Scaling (Qwen 3 VL): For larger datasets later on, I plan to "distill" Gemini’s visual reasoning into Qwen 3 VL 32B to create a local, cost-effective captioning engine.
- Bidirectional Training: I'm also considering training on pairs Clothed <-> Naked. Since base models are often SFW-aligned, teaching the transformation in both directions might help them understand the anatomy better.
4. Resources I've Analyzed
I've dug deep into what's currently available. Here is why I think we need a new approach:
- Datasets:
- Makki2104/difference_images_Cloth-Nude: It's huge, but unusable for high-precision DiT models. It lacks proper captions, contains censorship, and many pairs are too inconsistent.
- Xnsviel/anime-clothes-remover-nsfw: Much higher quality, but the variety is very homogenous (same style/composition), and the captions miss "hidden" anatomical details like genital shape or pubic hair.
- Scraping Strategy: I believe parsing metadata via DeepGHS to find clean parent/child posts is a better route than using bulk dumps.
- Models: Jonny001/Qwen-Image-Edit-Remove-Clothes, Phr00t/Qwen-Image-Edit-Rapid-AIO, nappa114514/Qwen-Image-Edit-2511-torn-clothes, chinmankokumin.
- ControlNets: Dresser/Undresser.
Summary: I am trying to move away from simple "tag matching" to "visual reasoning" in training. Am I on the right track with this YOLO -> Flux and Gemini -> Qwen approach?
Does this roadmap address the core issues of precision and visual logic, or am I missing something fundamental? I’m looking for feedback on the strategy as a whole-from the 'hardcoded prompt' overfitting and the reasoning bottleneck to the effectiveness of bidirectional training. Is this YOLO + Flux pipeline the right way to finally solve the anatomy erosion and consistency issues that current tools struggle with?